



Azure Synapse Analytics Continues to Break the Mold
- April 22, 2021
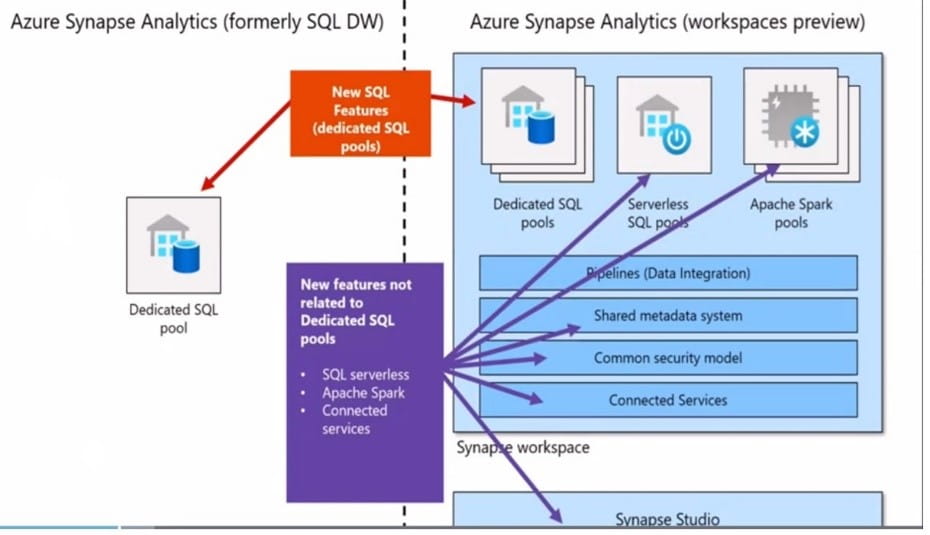
For the uninitiated, Microsoft describes Azure Synapse Analytics as bringing together the “best of SQL technologies used in enterprise data warehousing, Spark technologies use for big data, pipelines for data integration and ETL/ELT and deep integration with other Azure services like Power BI, CosmosDB and Azure ML.” The service is accessible from a single location giving data engineers, data scientists and more the ability to all work in the same interface and use the same tools across their specific areas. An added boon for ETL teams is that they can use Azure Event Hubs – Microsoft’s big data streaming platform – to stream into it.
What’s new?
Microsoft has added key new features and updated other functionality in Synapse Analytics. Specifically:
- SQL Serverless pools. Operating like a SQL server, you can now connect with the same tools. This new model for query processing allows your team to use both serverless and dedicated options.
- Apache Spark pools feature a new interface and now offers a Visual Studio IntelliSense view. Microsoft also notes that they’ve expanded the query optimization and execution performance for Apache Spark workloads, including the ability to auto-scale Spark clusters up and down on-demand.
- Linked Services allows operators to now link nearly anything that has to do with data to Synapse. While we like the link to CosmosDB and Azure ML best, you can link to anything, (including Spark, SQL Server, and Dedicated SQL pools), accessible with a single line command. Simply give it a name and a link and direct it to connect.
- Tight Azure ML integration includes the ability to store ONYX models in DataStore and access them via SQL, integration with AutoML, and the ability to use Python, Spark and Cognitive Services inside of the workspace.
Test drive
We gave the preview of Azure Synapse Analytics a trial run. It took fewer than 30 minutes to spin up; the workspace itself took less than a minute. Off to a speedy start, we dove in to take a closer look at the new and updated components:
- SQL Serverless Pools. Every workspace comes with a “built-in pool” that will scale as large as needed. Operating similarly to AWS Athena, SQL Serverless pools are ideal for data exploration, like querying files directly from ADLs. We also like them for data transformation because the pool is usable like any other SQL Database allowing you to write queries to transform data and create new objects. For example, you can query and write to a SQL data warehouse, a dedicated pool, Spark warehouse or Cosmos. All are available. Last, logical data warehouses are ideal SQL Serverless Pools use cases, allowing you to create most data objects, views, external tables and more in the pool.
We can also use SQL Serverless Pools to create a model and generate a predication. Taking a ML model and querying it with SQL, you can output it to Power BI and have it visually appear in Azure Synapse. It’s also worth noting that while the pool is on all the time, you only pay for it when you query it. At a run-rate of $5/TB scanned, the solution is quite affordable given that you’ve properly formatted your data.
- Spark Pools is a capability of Spark embedded in Azure Synapse that gives you the ability to spin up a Spark cluster to meet data engineering needs without the overhead of other Spark Platforms. This allows a Spark cluster to be quickly spun up within Synapse Analytics so that data engineers, data scientists, data platform experts, and data analysts can come together and meet their needs. This provides scale in an efficient way for Spark Clusters and it is integrated with the one-stop-shop data warehousing platform of Synapse.
While Spark can be used for most any data use case, Spark Pools can be used for a full production Data Lake, very large scale ETL and/or ETL/ELT layer for the data. We also like Spark pools for their ability to experiment with any size data and gain insights about the data. Also keep them in mind for preparing your data and cleaning it up, (it’s also an integrated experience for creating scripts that can do so); and Notebook allows you to access your data through a variety of languages. Notebook even allows you to change languages in the middle of a Notebook. (And, yes, .NET is offered.) A noteworthy side benefit of Spark pools is that it’s stored for you, so when you start a pool up, it’ll be there for you.
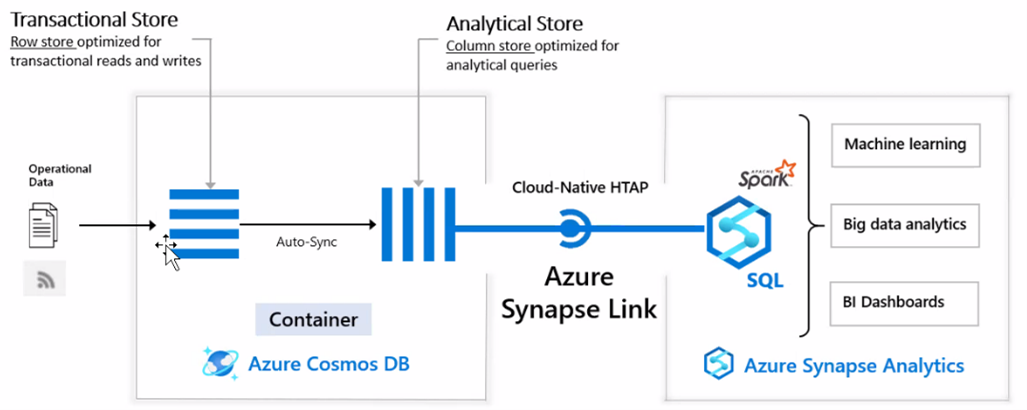
- Users can now access the Azure Cosmos DB analytical store through Azure Synapse Analytics. Azure Cosmos DB analytical store can be queried simultaneously by Azure Synapse Analytics’ different analytics runtimes as the analytical storage system has been separated from the analytical compute system. The Cosmos Analytical Store is NoSQL, which is a large positive for its ability to write and read very quickly. Yet, outside of these two activities, NoSQL falls short. To combat this, Synapse Analytics introduces auto sync. Operators simply turn on analytics when they create containers and every 2.5 seconds, auto sync will ‘flip’ the data, turning it into a column store, optimized for analytical inquiries, providing better read performance. This allows operators to conduct very near real time analysis, which couldn’t previously be done without writing it all yourself. Now, operators can use Spark and Serverless Pools to query the Cosmos Analytical store instead of the NoSQL store.
- The updated ingest function features tight integration with Azure Data Factory. If you’ve done any type of ETL into Azure, you’ve worked with Data Factory before. But, now it’s even better with Synapse. For example, if you use SQL Server Integration Services (SSIS) on site and migrate to Azure, those SSIS jobs can easily be used with Data Factory.
- Last, but certainly not least is the new Azure Purview-powered search in Azure Synapse Analytics workspaces. Introduced in preview, operators will be able to use the native Azure Purview powered search within Synapse Studio, giving them easier access to data. For example, operators can point Purview at a database, bucket, or series of buckets and it’ll get all the data which can then be enhanced with definitions, and more. It’s an enterprise data catalog that other clouds simply don’t have.
The new Azure Synapse has a lot to offer anyone in the organization with a data-centric role. From tighter integrations, to enhanced dashboarding, and even a vast set of example data sets and notebooks to learn from, Azure Synapse has managed to build on its initial promise to powerfully aggregate data integration, data warehousing, and data analytics in a single platform.
For additional reading on how your enterprise can benefit from cloud, be sure to subscribe to the Tech Blog below.
Subscribe to our blog